38 confident learning estimating uncertainty in dataset labels
REFLACX, a dataset of reports and eye-tracking data for localization of ... The set of labels used for each phase is listed in Table 2. Phase 1 went from November 11, 2020 to January 4, 2021, phase 2 from March 1, 2021 to March 11, 2021, and phase 3 from March 24, 2021 to... Diagnostics | Free Full-Text | MixPatch: A New Method for Training ... The second approach measures prediction uncertainty with values of confidence. The confidence level is the highest value from a probability distribution that can be extracted from the softmax layer. Methods based on the second approach can provide appropriately calibrated confidence information to limit the overconfidence issue.
Types of Analytics:Descriptive,Predictive,Prescriptive Analytics The four types of data analytics are- Descriptive, Diagnostic, Predictive, and Prescriptive. Descriptive analytics examines historical events and tries to find specific patterns in the data. Diagnostic analytics- It's a type of advanced analytics that looks at data or content to figure out what caused an event to happen.

Confident learning estimating uncertainty in dataset labels
Quantifying the Uncertainty for Speech Recognition Uncertainty measures how confident the model is in making its predictions [1]. Depending on the source of uncertainty, we can categorize it into two types: aleatoric and epistemic. The aleatoric type is a statistical uncertainty that appears due to an inherently random process. For example, the outcome of a coin flip has aleatoric uncertainty. Data for Product Managers (Part 2/2) | by Arnaud Dessein | May, 2022 ... Machine learning techniques are classically divided into 3 main kinds of problems: Supervised learning. We have a dataset with labeled data, and we train a model with an algorithm to predict future labels when we'll see unlabelled data. When some labels in the training dataset are missing, we call it semi-supervised learning. Batch Mode Active Learning | by Ahmet E. Bayraktar | ING Analytics ... There are multiple ways to measure the uncertainty of a sample, the most commonly used three strategies are as below: 1. Least Confidence Sampling 2. Margin Sampling 3. Entropy Sampling Let's say...
Confident learning estimating uncertainty in dataset labels. weijiaheng/Advances-in-Label-Noise-Learning - GitHub ICML 2022 [UCSC REAL Lab] To Smooth or Not?When Label Smoothing Meets Noisy Labels. [UCSC REAL Lab] Detecting Corrupted Labels Without Training a Model to Predict.[UCSC REAL Lab] Beyond Images: Label Noise Transition Matrix Estimation for Tasks with Lower-Quality Features.Robust Training under Label Noise by Over-parameterization. Estimating Instance-dependent Label-noise Transition Matrix ... なんもわからん人の論文読み会(Confident Learning)#6 - connpass ラベルミス等のデータの不確実性に対処する Confident Learning の論文を読みます。 Confident Learning: Estimating Uncertainty in Dataset Labels Finding millions of label errors with Cleanlab 今回は 5.2 Real-world Label Errors in ILSVRC12 ImageNet Train Dataset 以降を読んでいきます。 やらないこと 完璧に正しい理解をしようとしない 細かい箇所の理解が合っているかなどはあんまり追求しません 時間をかけてじっくり読みすぎない 数式の証明を深追いしない その他 途中での質問も歓迎です Uncertainty Estimation and Reduction of Pre-trained Models for Text ... Intrinsic uncertainty estimation provides the basis for our proposed data selection strategy: By filtering noise based on confidence thresholding, and mitigating exposure bias, our approach is shown to be effective at improving both performance and generalization in low-resource settings, in self-training, and active learning settings. 2 Background Uncertainty estimation based adversarial attack in multi-class ... Concisely, uncertainty quantification methods have appeared to detect data points that the model is not trained on such in deterministic uncertainty quantification (DUQ) [ 37 ], or to capture data points that fall near decision boundary such in Deep Ensembles [ 20] and Monte-Carlo dropout (MC-dropout) [ 13 ].
YOLO: Real-Time Object Detection Explained - V7 The object detection dataset that these models were trained on (COCO) has only 80 classes as compared to classification networks like ImageNet which has 22.000 classes. To enable the detection of many more classes, YOLO9000 makes use of labels from both ImageNet and COCO, effectively merging the image classification and detection tasks to only ... Set up AutoML for time-series forecasting - Azure Machine Learning In this article, you learn how to set up AutoML training for time-series forecasting models with Azure Machine Learning automated ML in the Azure Machine Learning Python SDK. To do so, you: Prepare data for time series modeling. Configure specific time-series parameters in an AutoMLConfig object. Run predictions with time-series data. Linear Regression in Python with Scikit-Learn - Stack Abuse If we plot the independent variable (hours) on the x-axis and dependent variable (percentage) on the y-axis, linear regression gives us a straight line that best fits the data points, as shown in the figure below. We know that the equation of a straight line is basically: y = mx + b. Where b is the intercept and m is the slope of the line. なんもわからん人の論文読み会(Confident Learning)#5 - connpass ラベルミス等のデータの不確実性に対処する Confident Learning の論文を読みます。 Confident Learning: Estimating Uncertainty in Dataset Labels; Finding millions of label errors with Cleanlab; 今回は 5. Experiments 以降を読んでいきます。 やらないこと. 完璧に正しい理解をしようとしない
Segmentation Only Uses Sparse Annotations: Unified Weakly and Semi ... The effect of semi-supervised learning L m s e The use of unlabeled data exhibits a significant performance gain. The consistency regularization, which aligns the probability map for unlabeled data, not only improves the accuracy of segmentation, DSC increase by 15.03% (65.29% vs. 50.26%) but also significantly reduces the false positive rate, HD and ASSD decrease by 18.27mm (63.72mm vs. 81 ... Federated learning of molecular properties with graph neural networks ... By substituting the formulation φ + into Equation 7, we obtain ω + ( x l, F l, F g) to measure the uncertainty of the training samples, and accordingly, we obtain FLIT+ by optimizing the objective as (Equation 11) L F L I T + ( x l) = ( 1 − exp ( − ω + ( x l, F l, F g))) γ ( L ( y ˆ l, y l) + Δ ( x l, F l)). Decision Tree - GeeksforGeeks A Decision tree is a flowchart like tree structure, where each internal node denotes a test on an attribute, each branch represents an outcome of the test, and each leaf node (terminal node) holds a class label. A decision tree for the concept PlayTennis. A tree can be "learned" by splitting the source set into subsets based on an attribute ... ULTRA: Uncertainty-aware Label Distribution Learning for Breast Tumor ... In this paper, to efficiently leverage the label ambiguities, we proposed an Uncertainty-aware Label disTRibution leArning (ULTRA) framework for automatic TC estimation. The proposed ULTRA first converted the single-value TC labels to discrete label distributions, which effectively models the ambiguity among all possible TC labels.
Isaac L. Chuang | DeepAI
🔎 What Are Query Strategies for Active Learning 📚? I. Uncertainty Sampling A machine learning model first makes predictions on unlabeled data points. Usually, those predictions come with confidence. And uncertainty sampling instructs the system to select examples based on confidence in prediction. How to leverage predicted confidence? There are four main ways: Simple uncertainty

Label errors of the original MNIST train dataset identified... | Download Scientific Diagram
Ramifications of incorrect image segmentations; emphasizing on the ... Initially, comparative experiments were performed alongside Bayesian uncertainty estimation and state-of-the-art confidence estimation methods on different datasets. These findings were then conducted by a comprehensive investigation of the impact of the confidence criterion, learning scheme, and training loss in this approach.

标注数据存在错误怎么办?MIT&Google提出用置信学习找出错误标注(附开源实现) - 知乎
Dynamic World, Near real-time global 10 m land use land cover mapping our approach also leverages weak supervision by way of a synthesis pathway: this pathway includes a replica of the labeling model architecture that learns a mapping from estimated probabilities...
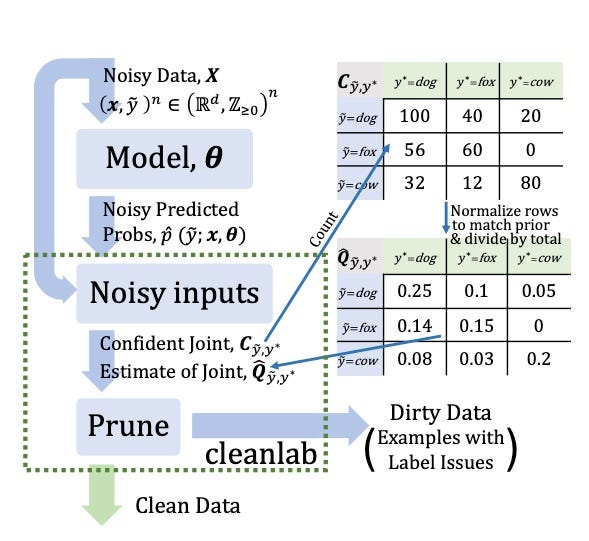
Are Label Errors Imperative? Is Confident Learning Useful? - Pasa En Tu Ciudad
Active Learning Overview: Strategies and Uncertainty Measures Least confidence is the simplest and most used method, it gives you ranked order of predictions where you will sample items with the lowest confidence for their predicted label. 3.2. Margin of confidence sampling. The most intuitive form of uncertainty sampling is the difference between the two most confident predictions.
![[Paper Reading]Learning with Noisy Label-深度学习廉价落地 - 知乎](https://pic2.zhimg.com/v2-80277171b5896eb794b5600dc526a8e5_r.jpg)
[Paper Reading]Learning with Noisy Label-深度学习廉价落地 - 知乎
Sensors | Free Full-Text | Remaining Useful Life Prediction Method for ... Therefore, to obtain an accurate RUL estimation while considering uncertainty, it is necessary to incorporate uncertainty features into deep-learning-based methods. Ghahramani [ 22] stated that the Bayesian method is a promising measure of uncertainty, and Bayesian inference can be used as a learning tool to address uncertainty in deep learning.

(PDF) Confident Learning: Estimating Uncertainty in Dataset Labels
Uncertainty handling in convolutional neural networks Results show that two-path NCNN outperforms CNN by 5.11% and 2.21% in 5 pairs (training, test) with different levels of noise on MNIST and CIFAR-10 datasets, respectively. Finally, NVGG-Net increases the accuracy by 3.09% and 2.57% compared to VGG-Net on CIFAR-10 and CIFAR-100 datasets, respectively. Introduction

Learning with noisy labels | Papers With Code
Batch Mode Active Learning | by Ahmet E. Bayraktar | ING Analytics ... There are multiple ways to measure the uncertainty of a sample, the most commonly used three strategies are as below: 1. Least Confidence Sampling 2. Margin Sampling 3. Entropy Sampling Let's say...
Post a Comment for "38 confident learning estimating uncertainty in dataset labels"